Work in progress!
Deterministic Finite Automata
Deterministic finite automata (DFAs) are a type of finite state machine.
They can only be in one state at a time, and do not allow for transitions on the null symbol.
The transition function δ is defined for all state-symbol pairs.
Transitions not depicted on the state-transition diagram are assumed to go to an implicit dead state.
Depicted is the state-transition diagram for a DFA that recognizes binary strings ending in 1.
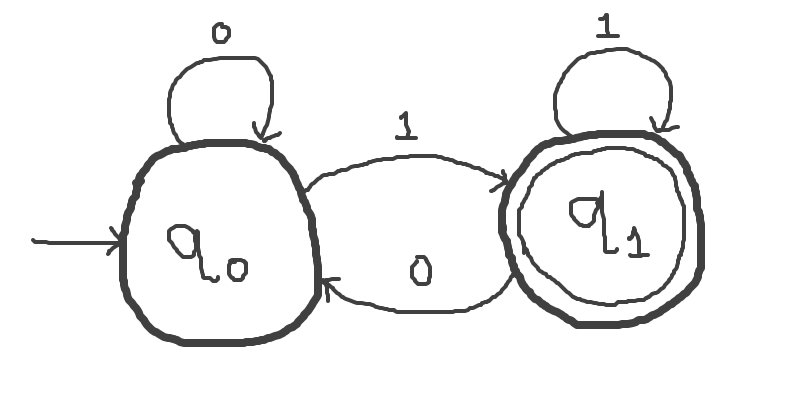
The initial state is depicted with an incoming arrow from nowhere. Here, q0 is the initial state.
The final states are depicted with double circles. Here, q1 is the only final state.
Formally, we say S = q0 and F = { q1 }.
There are four transitions:
- δ(q0, 0) = q0
- δ(q0, 1) = q1
- δ(q1, 0) = q0
- δ(q1, 1) = q1
The transition function δ can be described with a table.
| 0 | 1 | |
| q0 | q0 | q1 |
| q1 | q0 | q1 |
Consider the input word 11001.
The DFA begins in the initial state q0.
The transitions taken are as follows:
- S = q0
- δ(q0, 1) = q1
- δ(q1, 1) = q1
- δ(q1, 0) = q0
- δ(q0, 0) = q0
- δ(q0, 1) = q1
This demonstrates that the transition taken depends only on the current state and the next input symbol.
Because the last output, q1, is a final state, the DFA recognizes the input word.
We say that 11001 is in the language recognized by the DFA.
Constructing DFAs from Language Descriptions
Recall that recognizers define the language they accept.
Example 1: Matching a single word
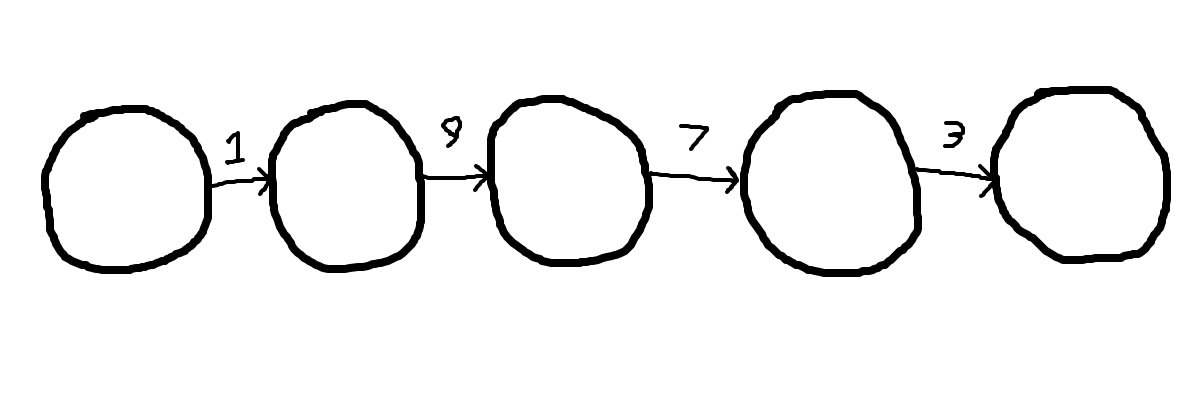
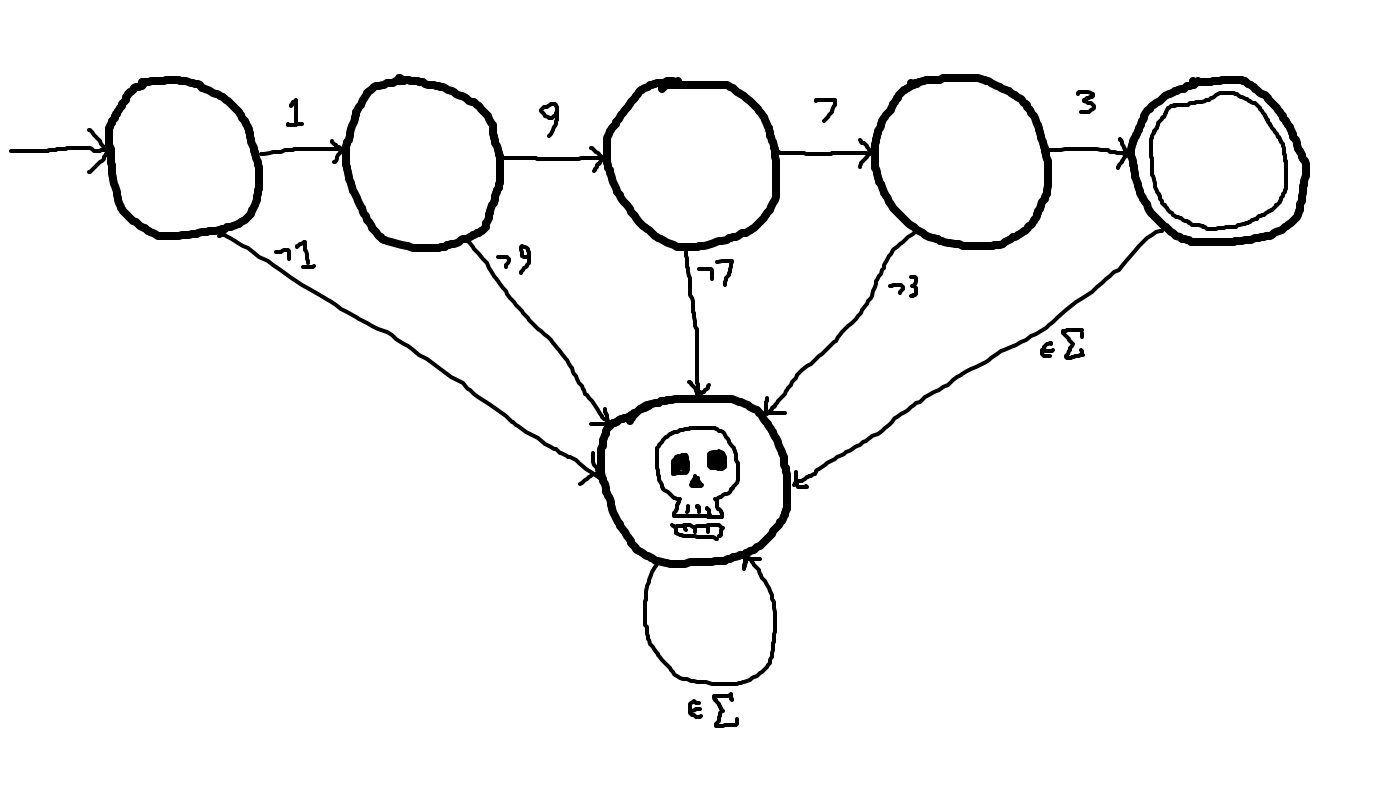
Suppose we wished to design a combination lock with the password "1973".
We can model the behavior of the lock with a deterministic finite automaton where Σ = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }.

Matching a single word is simple. Begin with a linear chain of states, where each transition corresponds to the respective digit of the password.
Next, mark the first state as the initial state, and the last state as a final state.
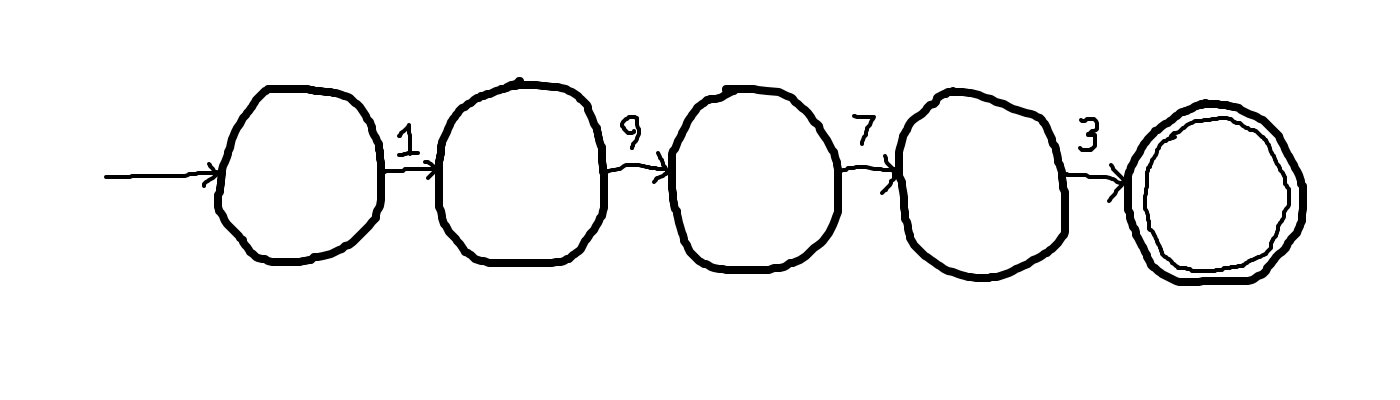
The unspecified transitions are defined to go to an implicit dead state.
Example 2: Matching a substring
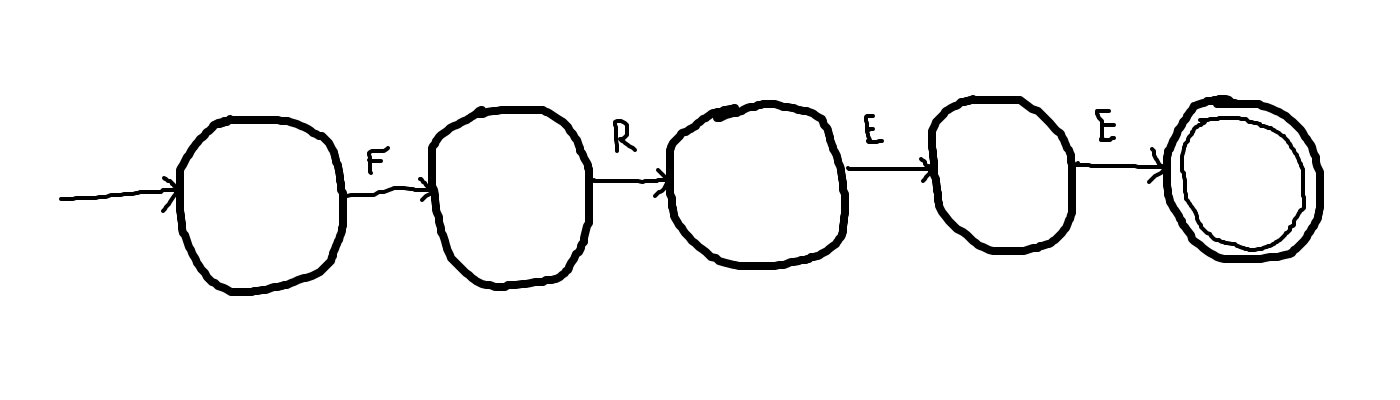
A basic email spam filter scans all incoming message bodies for certain key words.
Assume a significant amount of spam emails contain the word "free".
We can model the spam heuristic using a deterministic finite automaton where Σ is the set of characters that may appear in an email body.
Matching a substring is similar to matching a single word. Begin with a linear chain of transitions.
Mark the first state as the initial state and the last state as a final state.
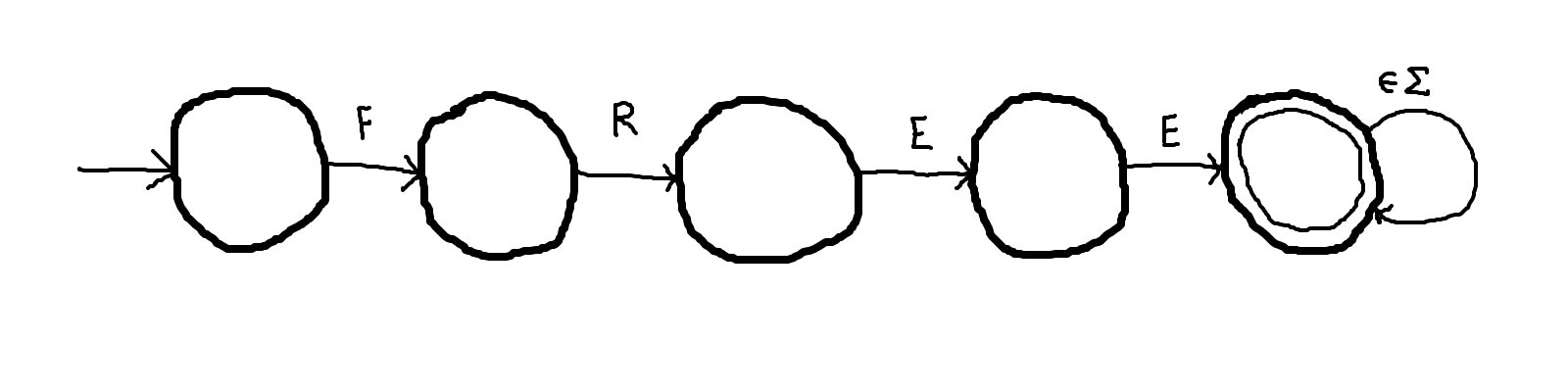
Once the word has been matched, the machine must remain in the final state.
This can be accomplished with a loop on the final state.
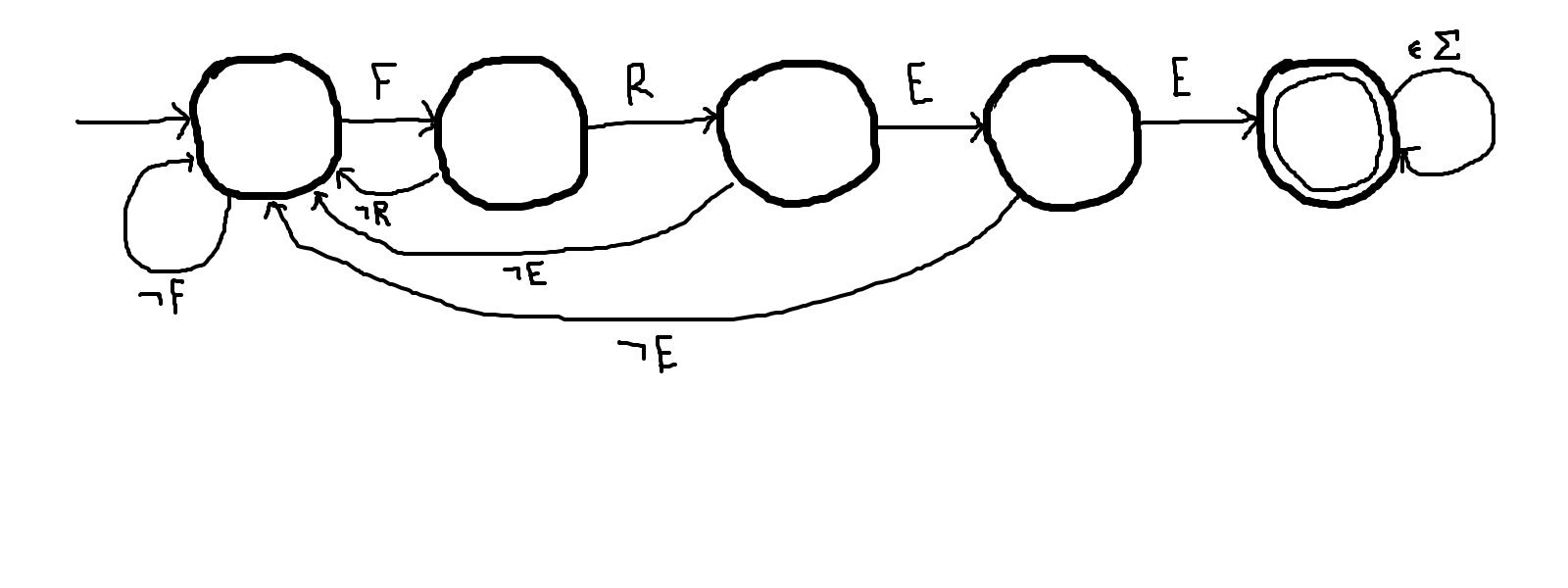
Rather than going to a dead state when failing to match the word, the machine should keep searching for it.
We can accomplish this by instead looping back to the initial state upon failure.
Example 3: Counting substrings
DNA is made up of four different nucleotides:
- Adenine (A)
- Cytosine (C)
- Guanine (G)
- Thymine (T)
Forensic experts are analyzing the scene of a burglary.
DNA evidence may point to a notorious wanted cat burglar.
Through DNA sequencing, the cat burglar's DNA is known to contain the nucleotide sequence "CAT" exactly twice.
We can model a DNA sequencer to determine whether the perpetrator was the notorious cat burglar.
To design a DFA that matches a substring multiple times, begin with a DFA that matches it at least once.
We'll call this the CAT scanner.
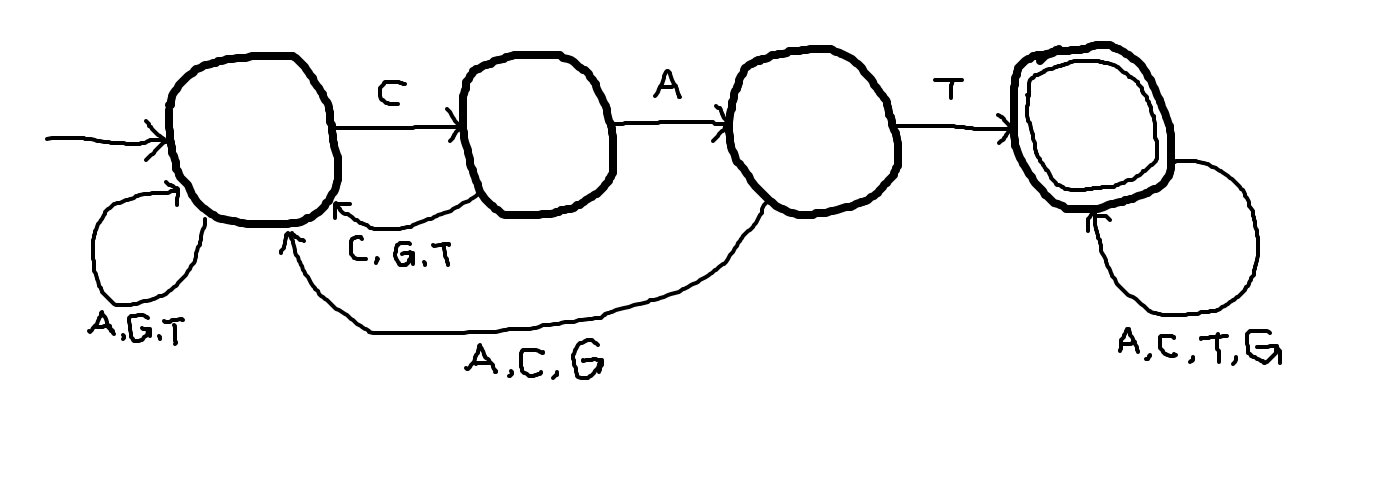
Matching the word twice means appending two CAT scanners together.
The final state of the first scanner can be replaced with the initial state of the second scanner.
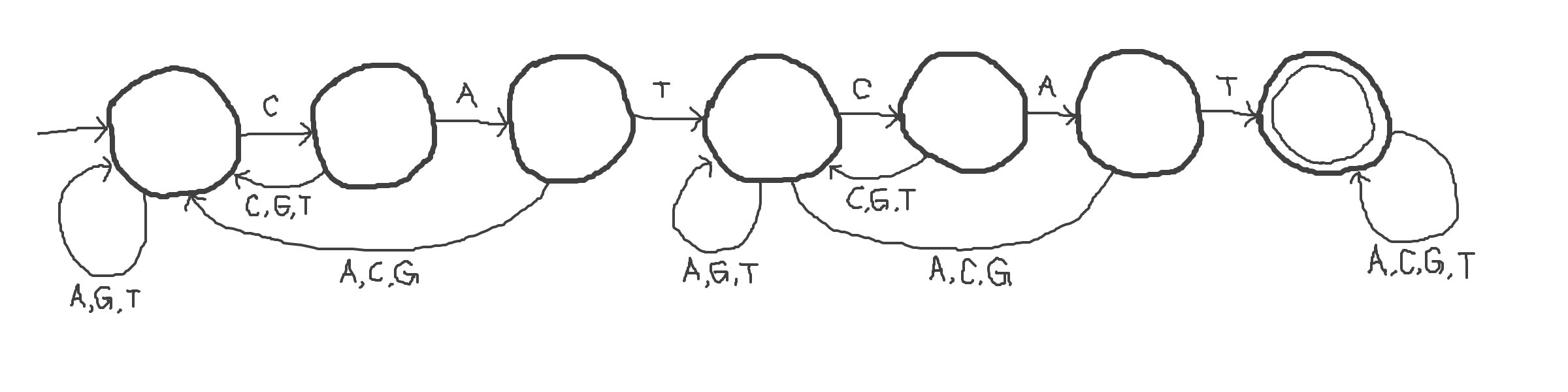
This DFA recognizes all words that contain the substring CAT at least twice.
Notice: after matching the first CAT substring, there is no path returning to the first few states.
This prevents the DFA from forgetting it matched the first CAT.
Finally, we need to reject the word if it contains a third CAT.
We can recognize the word by appending a modified version of the CAT scanner.
This version will have its final states and non-final states swapped.

Determining the Language Recognized by a DFA
Informally, we use natural language descriptions to define languages.
Languages can be more rigorously defined using automata like DFAs.
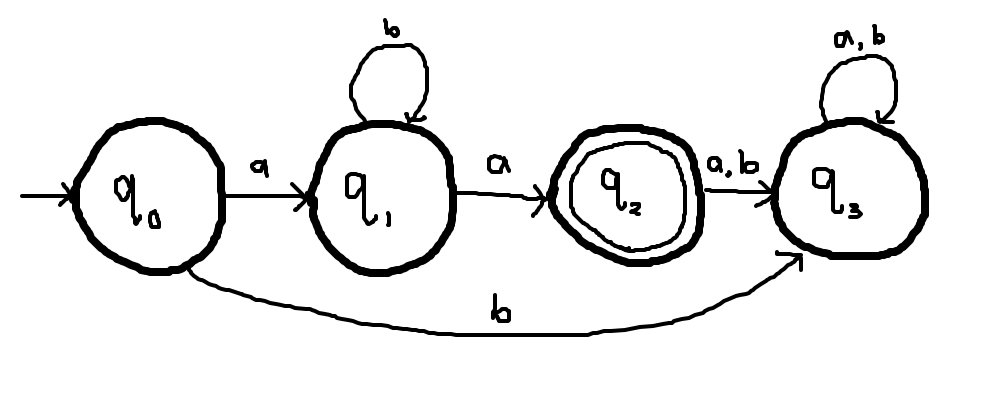
Example 1: DFA without loops
If a DFA has no loops, the language it recognizes is finite.
(Technically every DFA has a loop, otherwise it is in the implicit dead state)
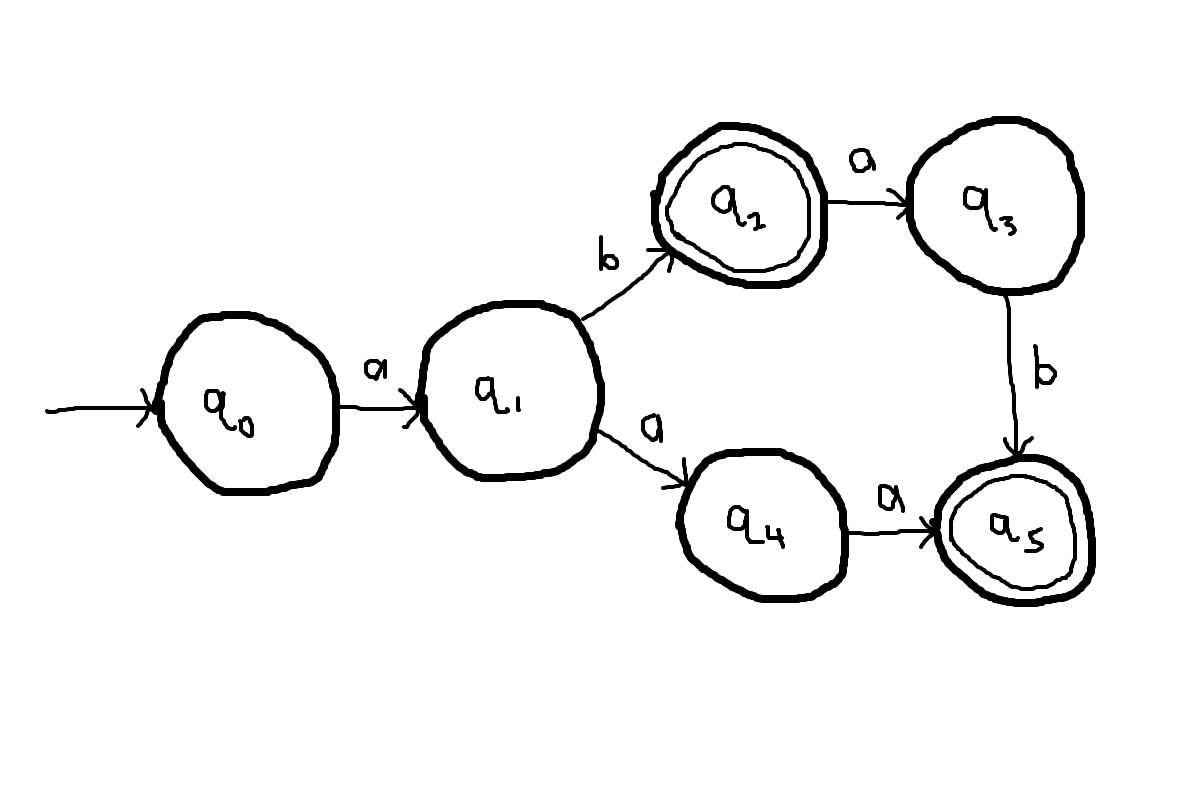
The language recognized by such a DFA can be determined by tracing each possible path from the initial state to a final state.
- "ab", derived from the path q0 → q1 → q2
- "aaa", derived from the path q0 → q1 → q4 → q5
- "abab", derived from the path q0 → q1 → q2 → q3 → q5
Example 2: DFA with simple loops